Appendix D — Context dependence of leveling and sharpening
D.1 Supplementary Methods
D.1.1 Additional information on stimulus construction
To calculate the specific values on the two feature dimensions, the following steps were taken. First, the length between the minimum and maximum value of the dimension which has the least space to vary relative to the border of the canvas, i.e. the available length, was determined. To compute the available length, a predefined margin was multiplied by two and subtracted from the total length of the dimension which had the least space to vary. This margin was necessary to allow for the sharpening of a dimension. It was defined as one-fifth of the total length. This first step could be mathematically defined as follows: \[availableLength = totalLength - \frac{2*totalLength}{5}\]
Second, the size of the steps between the four values of a dimension was computed and centered around their midpoint1. The largest steps were defined as one-third of the available length, i.e., \[step_{largest} = \frac{availableLength}{3}\] whereas the smallest steps were defined as one-fourth of the largest steps2, i.e., \[step_{smallest} = \frac{step_{largest}}{4}\]
Third, these steps were randomly paired per series. For instance, a stimulus in series A could have had the second largest value of the largest steps assigned to the first dimension, and the smallest value of the smallest steps assigned to the second dimension. Fourth, the values of the dimensions of the basic shapes that were not varied, were defined as the mean of the varied dimension of the other basic shape containing a variable dimension. Because of the nature of the task, for both series, only two out of four stimuli could serve as the target, namely those with the maximum and minimum value on the dimension with the largest variability. Because of the random pairing of values on the dimensions with largest and smallest variability, the value of the target on the dimension with minor variability could either have a minimum or maximum value as well (i.e., an extreme value), or could be a value in-between (i.e., a non-extreme value).
D.1.2 R packages used
As indicated in the Methods section, for all our analyses we used R (Version 4.0.4; R Core Team, 2021) and the R-packages brms (Version 2.16.1; Bürkner, 2017, 2018, 2021), cowplot (Version 1.1.1; Wilke, 2020), dplyr (Version 1.0.10; Wickham, François, et al., 2022), forcats (Version 0.5.2; Wickham, 2022), ggdist (Version 3.0.0; Kay, 2021a), gghalves (Version 0.1.3; Tiedemann, 2020), ggplot2 (Version 3.3.6; Wickham, 2016), ggstance (Version 0.3.5; Henry et al., 2020), here (Version 1.0.1; Müller, 2020), htmltools (Version 0.5.3; Cheng et al., 2021), knitr (Version 1.39; Xie, 2015), papaja (Version 0.1.1; Aust & Barth, 2022), patchwork (Version 1.1.2; Pedersen, 2022), purrr (Version 0.3.4; Henry & Wickham, 2020), Rcpp (Eddelbuettel & Balamuta, 2018; Version 1.0.9; Eddelbuettel & François, 2011), readr (Version 2.1.2; Wickham, Hester, et al., 2022), rstan (Version 2.21.2; Stan Development Team, 2020a), StanHeaders (Version 2.21.0.7; Stan Development Team, 2020b), stringr (Version 1.4.0; Wickham, 2019), tibble (Version 3.1.8; Müller & Wickham, 2022), tidybayes (Version 3.0.1; Kay, 2021b), tidyr (Version 1.2.1; Wickham & Girlich, 2022), tidyverse (Version 1.3.2; Wickham et al., 2019), and tinylabels (Version 0.2.3; Barth, 2022).
D.1.3 Preprocessing of drawing data
To be able to analyze the drawing data, rather extensive preprocessing was required. First, shapes that were located outside of the drawing canvas (with an additional margin of 5 units added) were removed from the drawing data. This resulted in the removal of 215 shapes, coming from 171 of the 13032 drawings. We then counted the number of shapes of each type on the canvas and excluded drawings that had an incorrect number of rectangles or triangles (203 of 13032 drawings, 1.56%).
Second, we determined which drawn shape contained which of the relevant feature dimensions, based on the relative horizontal or vertical position (depending on the design in question) of the two drawn shapes on the canvas. If an equal horizontal or vertical position of the two drawn shapes made it impossible to determine which drawn shape contained which feature dimension, the drawing was excluded from analyses (7 of 12829 drawings, 0.05%).
Third, for the 20 out of 24 designs containing background figures, the position of the drawn shapes relative to the background figures was checked (specific exclusion criteria were design-dependent). In this way, 44 additional drawings were excluded (0.34%). This check also identified 115 drawings where the background figure was interpreted as a different shape than was intended, which were excluded from analyses as well (115 out of 12778 drawings, 0.9%).
Fourth, for the four designs without background figure(s), the relative placement of the drawn shapes was checked. Following this check, 11 drawings were excluded (0.09%).
Fifth, the orientation and the point location of the shapes was scrutinized, and the value for the point location was adapted when needed (i.e., because of a combination of mirroring and orientation parameters of the drawn shapes). This step excluded 22 additional drawings (0.17%). In total, 380 out of 13032 drawings were excluded so far (2.92%).
After excluding drawings not surviving the checks above, some of the absolute feature dimension values for the drawings needed rescaling: the values for drawings without background shapes (i.e., drawings for designs 2, 4, 5, and 18) and the values for drawings where the background shape was not necessarily used for scaling (i.e., drawings for designs 1 and 6). More specifically, we rescaled the drawings in such a way that the height or width of the drawn shape for which this feature was not varied served as a reference for the drawn shape in which this dimension was varied, so that the ratio between the two heights or widths was kept constant. This rescaling was needed to be able to compare the drawn feature values with the target values on each dimension.3
Although the rescaled absolute drawn values can be used directly for qualitative comparisons across designs (i.e., proportion of times a feature was leveled or sharpened in each context and variability condition), an additional standardization was needed to make quantitative comparisons across designs possible. All feature values were therefore divided by the available range for leveling and sharpening combined. In this relative measure, a value of one indicates use of all available space to draw the feature, with values ranging from zero to one (or larger than one if the feature was drawn larger than the available space).
Due to a programming error in the online experiment for the first wave of data collection, information concerning which figure served as target in a particular trial (i.e., minimum or maximum on the major feature dimension) was not saved, for 6326 out of 12630 drawings (50.09%). We therefore defined the extreme value that was closest to the drawn value on the major feature dimension as the target value on the major dimension, and in that way also determined the target value on the minor feature dimension. This is a conservative assumption that can only diminish the effect size of our results, as for those drawings for which no actual target information was available, it minimized leveling and sharpening for the major feature dimension (i.e., to one side of the mean value on the major feature dimension). To estimate the accuracy of this target assignment method, we compared assumed targets with actual targets for the part of the sample for which target information was saved. In this part of the sample (6304 drawings), an incorrect target was assigned for 40 drawings (0.63%), and no target could be assigned for 58 drawings (0.92%) because the drawn value was equally far from both targets or because target assignment differed when either the absolute or the relative values were taken into account.
Drawings for which no actual target information was available and in which a different target was assumed depending on whether the absolute or relative values were taken into account and/or drawings in which the value on the major feature dimension was equally far from the minimum and maximum target value (making it impossible to retrieve the target value on the minor feature dimension) were excluded from analyses (57 of 12630 drawings, 0.45%). As the wrong figure (with an in-between value rather than an extreme value on the major feature dimension) was mistakenly assigned as minimum target for series B of design 5 in the close context, all drawings of design 5 in series B where the minimum target was assigned were excluded, both those presented in close and far context (105 of 12573 drawings, 0.84%).
D.1.4 Bayesian hierarchical model implementation details
D.1.4.1 Qualitative data
We fitted a hierarchical Bayesian logistic regression model to the proportion of times a dimension was sharpened, with context, variability, and their interaction as fixed effects and feature dimension and participant ID as random effects for both intercept and slopes:
\[\begin{align*} \begin{split} sharpening \sim & \:Intercept + context + variability + context:variability \\ & + (1 + context + variability + context:variability \; || \; conceptdim) \\ & + (1 + context + variability + context:variability \; || \; pp\_id) \end{split} \end{align*}\]
As priors, we specified a normal distribution with a mean of zero and a standard deviation of 2 for the intercept, a normal distribution with a mean of zero and a standard deviation of 2 for the slopes, and an inverse gamma distribution for the standard deviations, with an alpha parameter of 2 and a beta parameter of 1. We used 4 chains consisting of 8000 iterations, with 4000 warmup iterations per chain.
We fitted models with the same specifications for the traditional and the alternative definitions of sharpening, as well as for the definition of being in target range, leveling, and sharpening including a neutral category. Regarding the latter, in the model for sharpening, the neutral category and the leveling responses were collapsed, in the model for leveling the neutral category and the sharpening responses were collapsed, and in the model for being in the target range the leveling and sharpening responses were collapsed.
D.1.4.2 Quantitative data
We fitted a hierarchical Bayesian Gaussian regression model to the signed difference between the drawn and target value (values relative to the available drawing space for the feature dimension in question), with context, variability, and their interaction as fixed effects and feature dimension and participant ID as random effects for both intercept and slopes:
\[\begin{align*} \begin{split} rel\_targetdiff \sim & \:Intercept + context + variability + context:variability \\ & + (1 + context + variability + context:variability \; || \; conceptdim) \\ & + (1 + context + variability + context:variability \; || \; pp\_id) \end{split} \end{align*}\]
As priors, we specified a normal distribution with a mean of zero and a standard deviation of 2 for the intercept, a normal distribution with a mean of zero and a standard deviation of 2 for the slopes, and an inverse gamma distribution for the standard deviations, with an alpha parameter of 2 and a beta parameter of 1. We used 4 chains consisting of 8000 iterations, with 4000 warmup iterations per chain.
D.2 Supplementary Results
D.2.1 Additional qualitative results for the traditional interpretation of leveling and sharpening (binarized; relative values)
When inspecting the standard deviations for the feature dimension random effects (see Figure D.1), it becomes clear that the estimated variability between feature dimensions is larger for the differences between the variability conditions than for the context effect: Whereas for almost all feature dimensions, the estimated sharpening probability was higher in the close than in the far context, not all feature dimensions showed a higher sharpening probability in the major variability condition (see Figure D.2). That the highest density continuous intervals are wider for the effect of context than for the differences between the variability conditions is potentially a consequence of the difference in the number of trials per condition involved in the comparison: for a context comparison, maximally 12 trials per condition per participant, whereas for a variability or extremeness comparison, maximally 24 trials per condition per participant were involved. The estimated variability between feature dimensions was higher than the estimated variability between participants (see also Figure D.3), which is potentially also a consequence of the limited number of data points per participant in comparison to the number of data points per feature dimension.
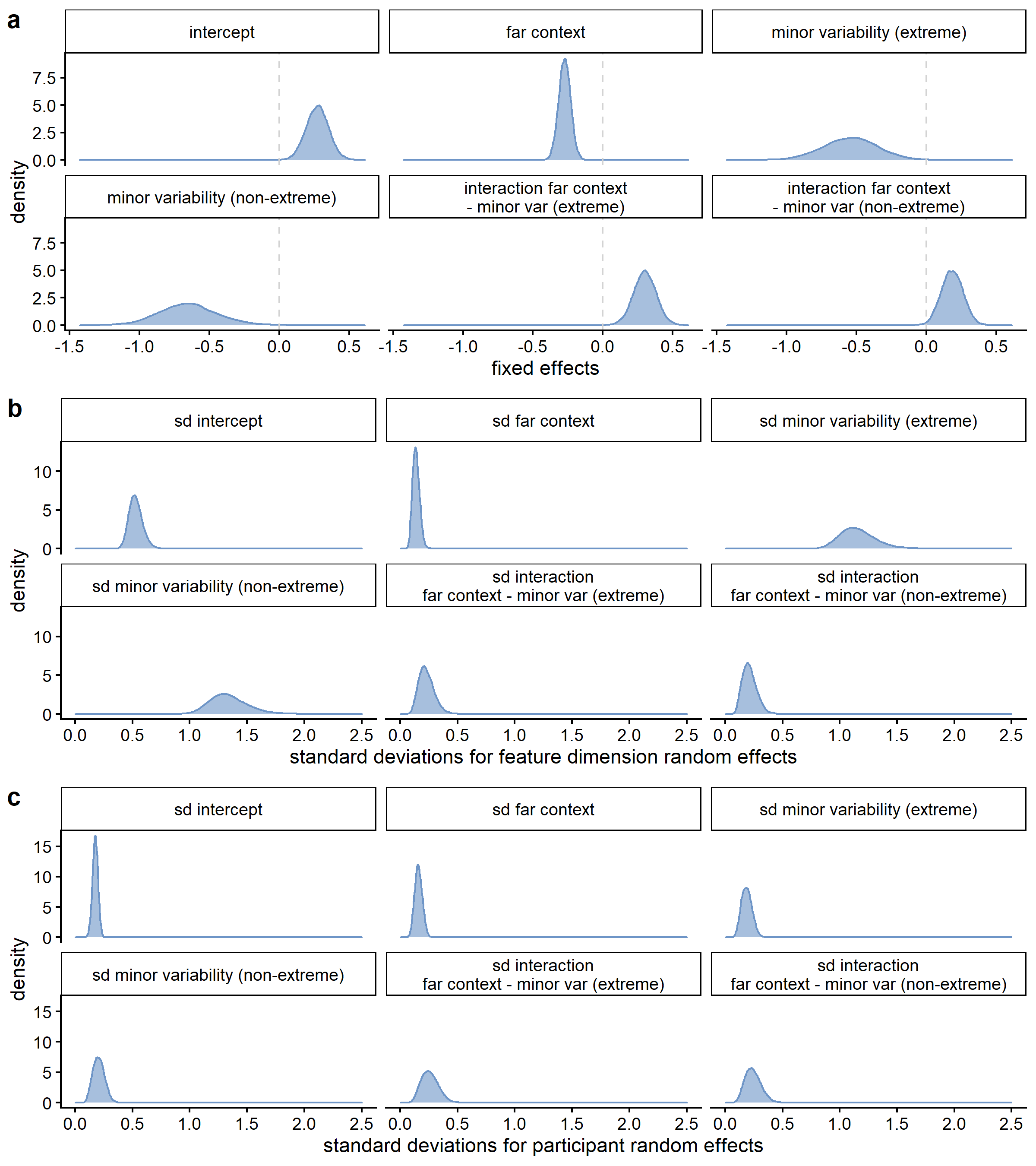
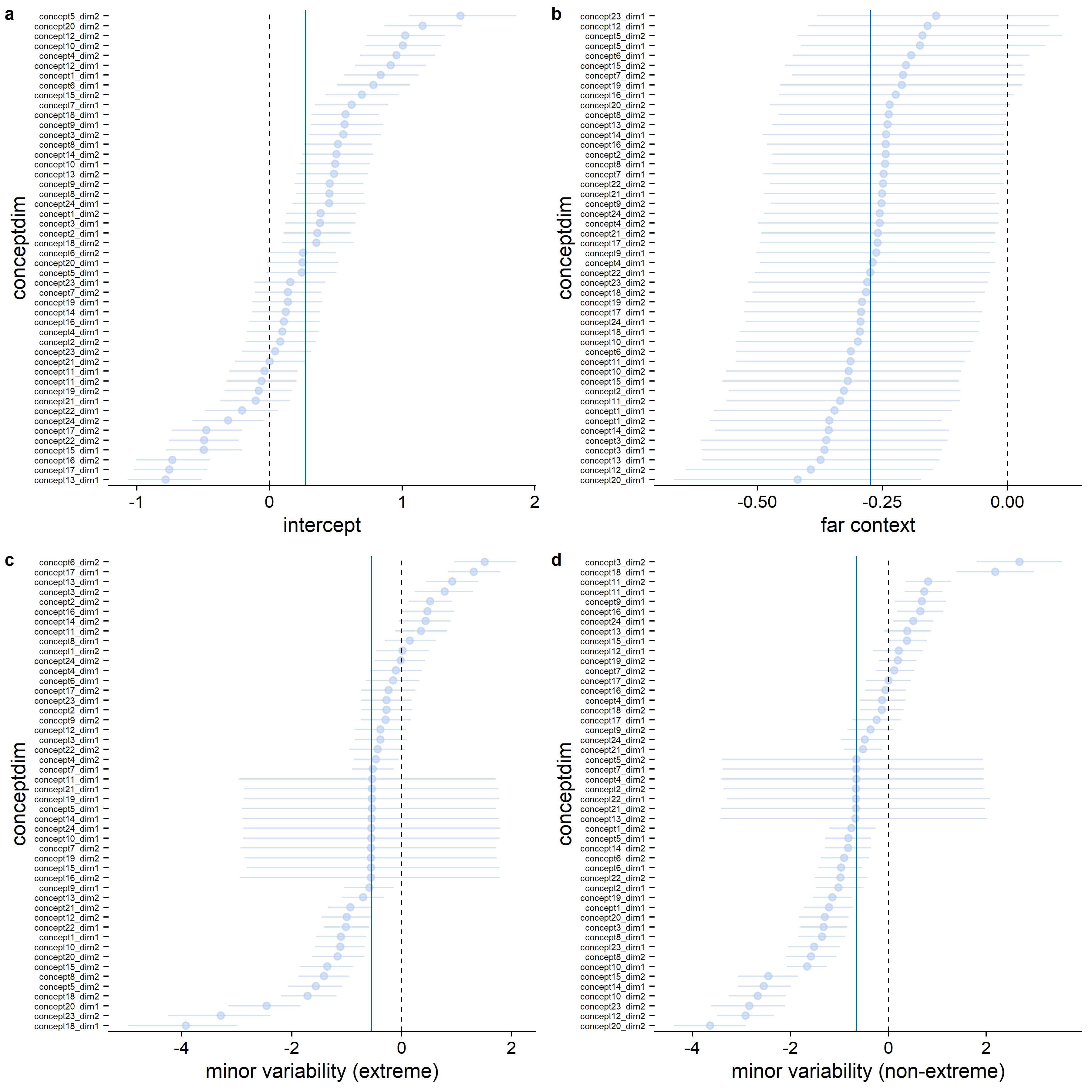
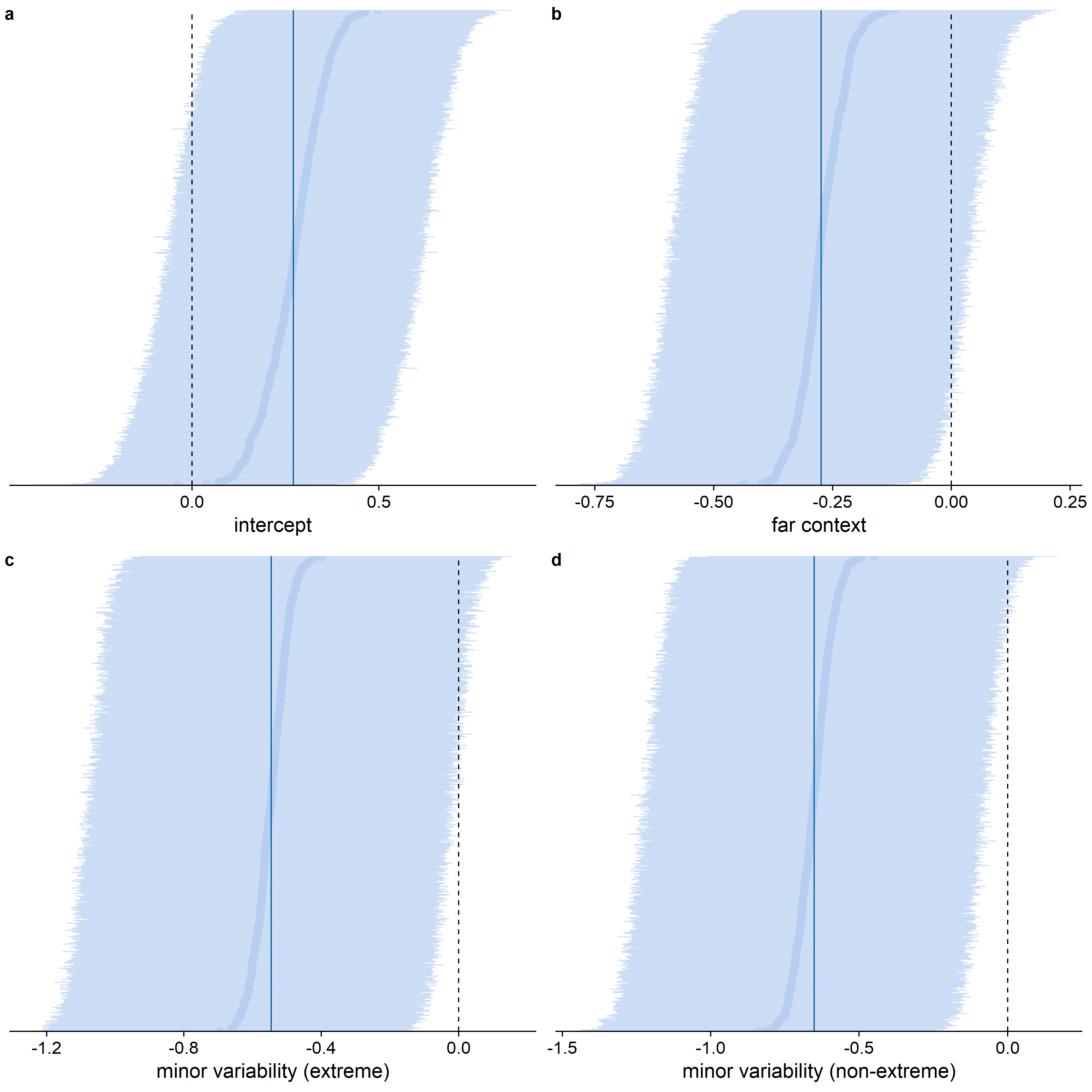
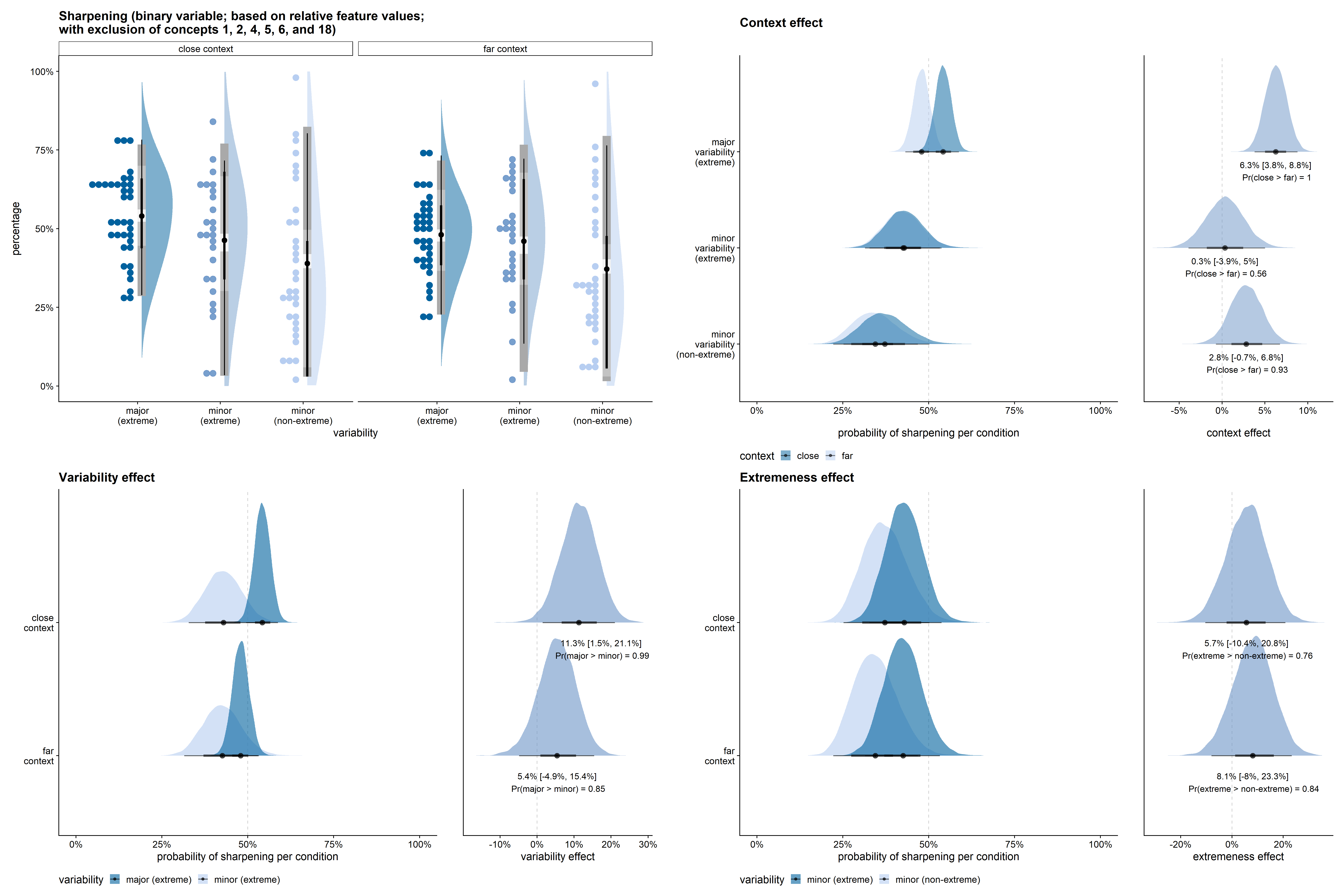
Figure D.4 shows the results for the equivalent qualitative model of sharpening based on the absolute rather than the relative feature values. Figure D.5 shows the results for the qualitative model of sharpening based on the relative feature values, but with exclusion of concepts 1, 2, 4, 5, 6, and 18.
D.2.2 Qualitative results for the alternative interpretation of leveling and sharpening (binarized; relative values)
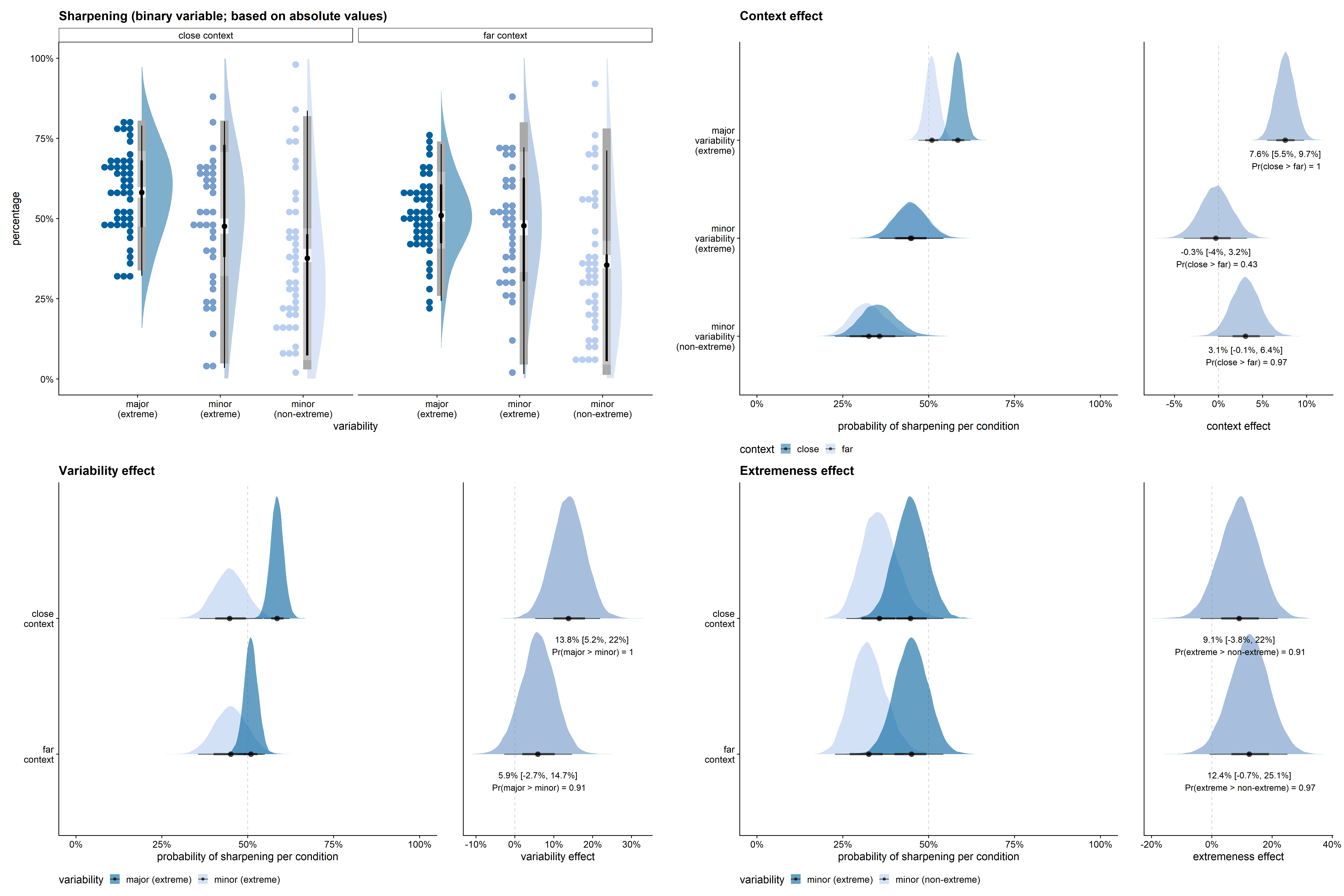
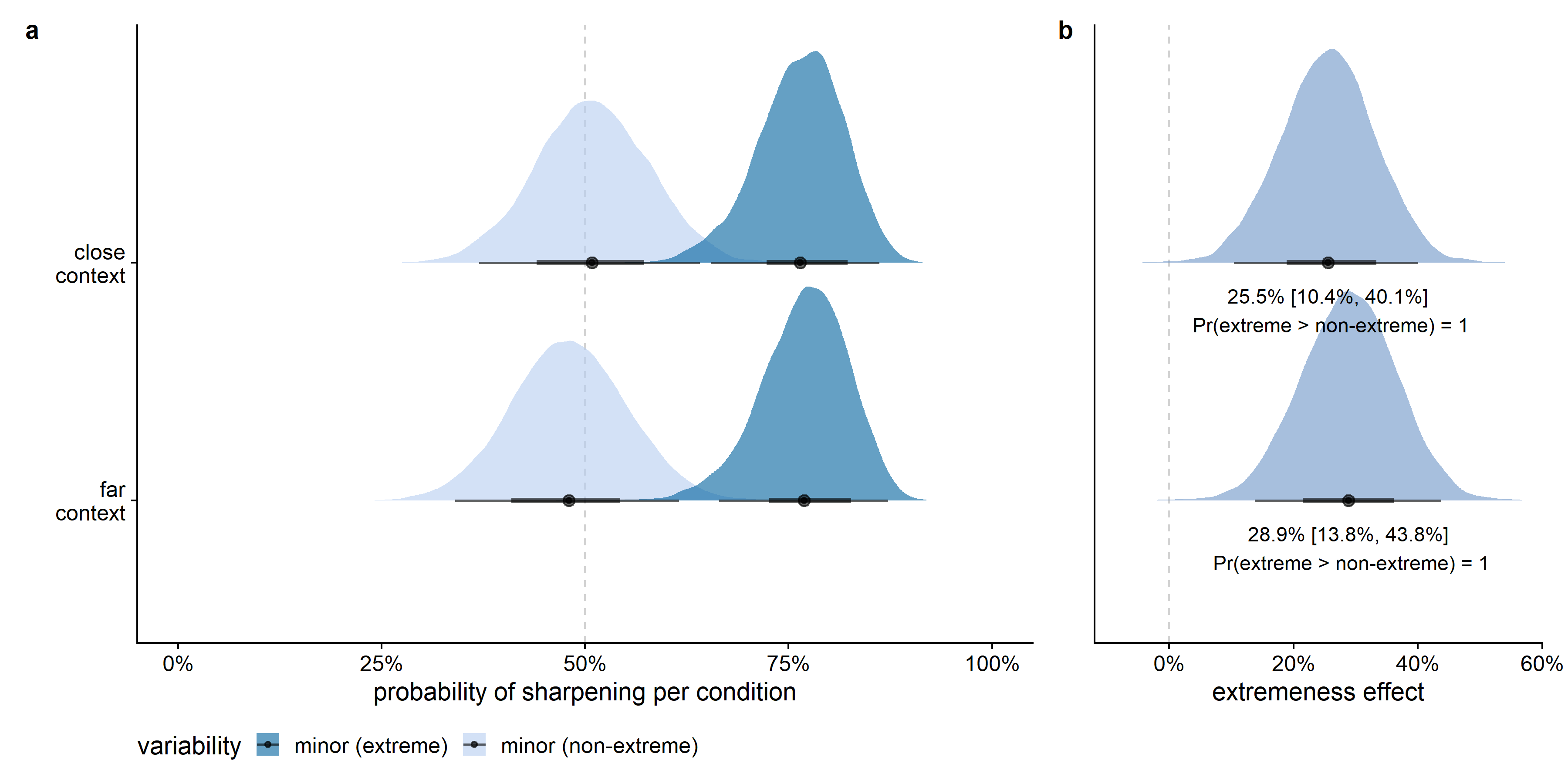
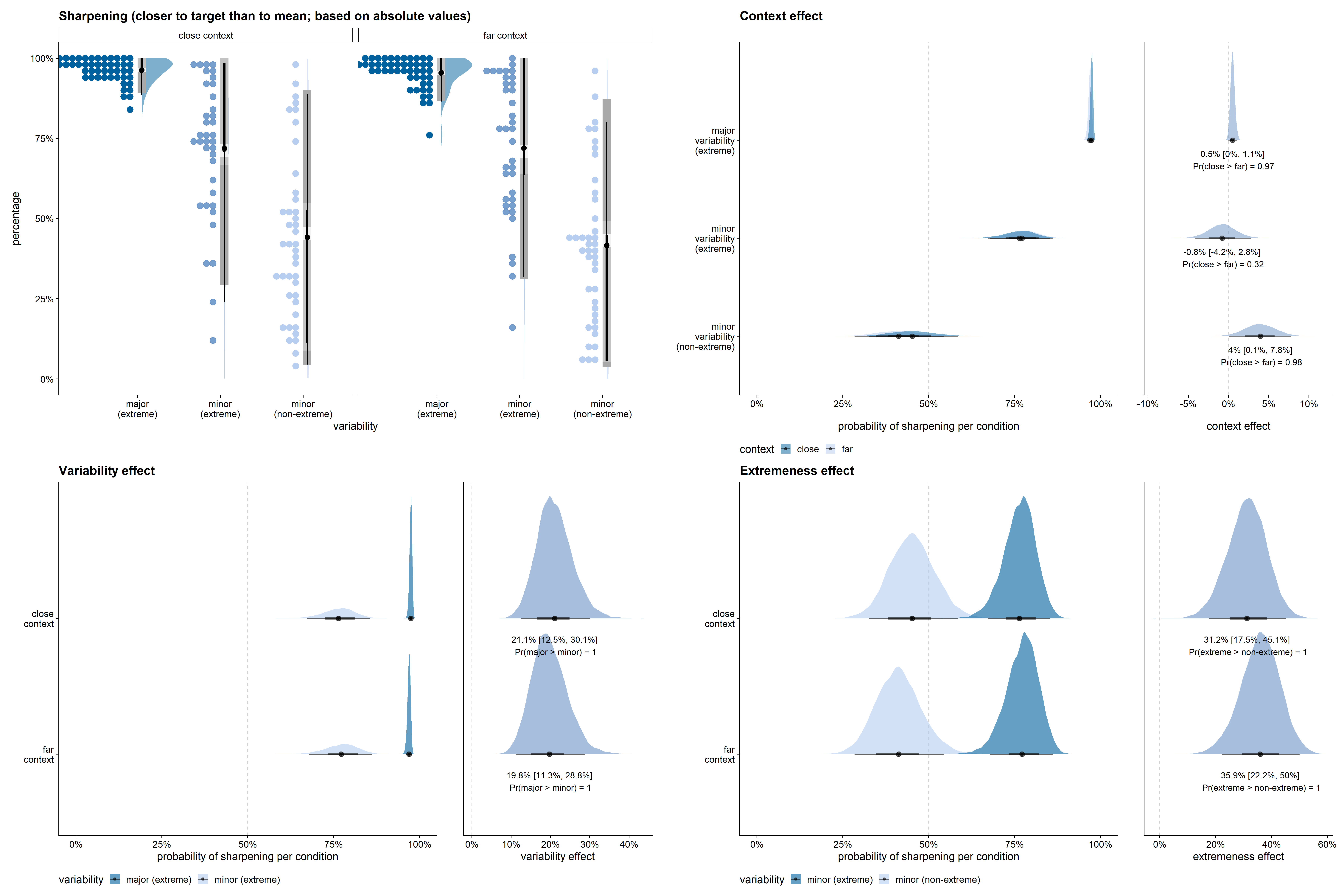
In Figure D.6, sharpening is defined as a drawn value closer to the target value than to the feature dimension’s mean. Defining sharpening in this manner, increased the differences between the three variability conditions and decreased the size of the context effect. The results stayed in the expected direction, however: sharpening was more likely for the major variability dimension than for the minor variability dimensions, and there was a tendency for sharpening to be more common in the close than in the far context. Furthermore, also using this definition of sharpening, there was much more variability in the percentage of sharpening across feature dimensions in the minor variability conditions than in the major variability condition.
Figure D.7, Figure D.8, and Figure D.9 give the posterior estimates from the model per context and variability condition, and compare the slope strengths across conditions for the effects of context, variability, and extremeness, respectively. In the major variability condition, the posterior probability of the proportion of sharpening in the close context to be larger than in the far context was 93%. Even though the direction of the effect was highly probable in the expected direction, given this alternative definition of leveling and sharpening, the context effect was very limited in size (see Figure D.7).
The effect of variability, however, was very large given this alternative interpretation of leveling and sharpening (see Figure D.8). In all posterior samples, the probability for an extreme value on the major feature dimension to be sharpened was larger than for an extreme value on a minor feature dimension. Given that the model is a good approximation of the data, the data provide evidence for a clear effect of variability in both the close and far context conditions.
Also the effect of being one of the extrema on the feature dimension was very large given this alternative interpretation of leveling and sharpening (see Figure D.9). In all posterior samples, the probability for an extreme value on the minor feature dimension to be sharpened was larger than for a non-extreme value on a minor feature dimension. Given that the model is a good approximation of the data, the data provide evidence for a clear effect of extremeness in both the close and far context conditions.
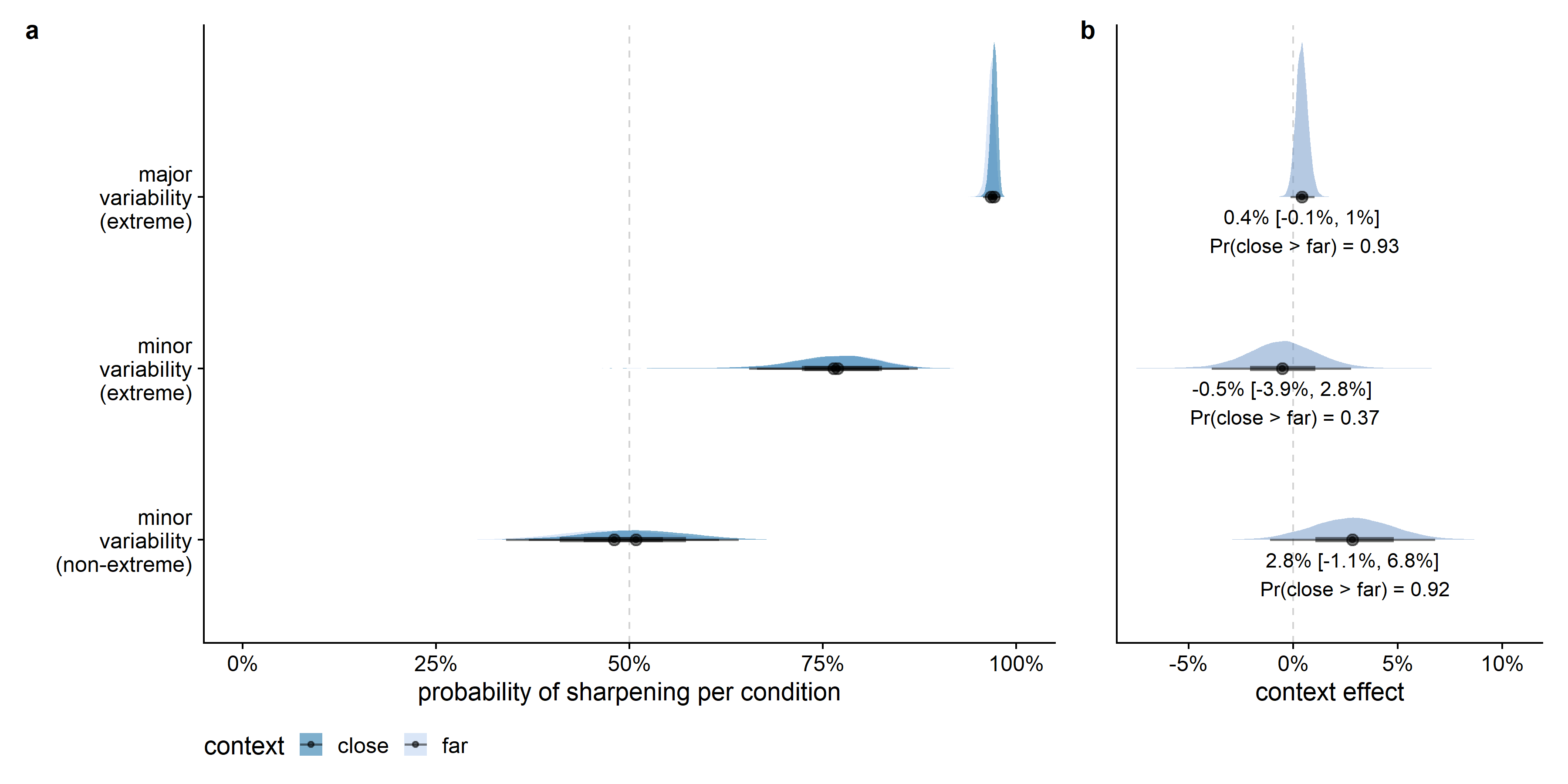
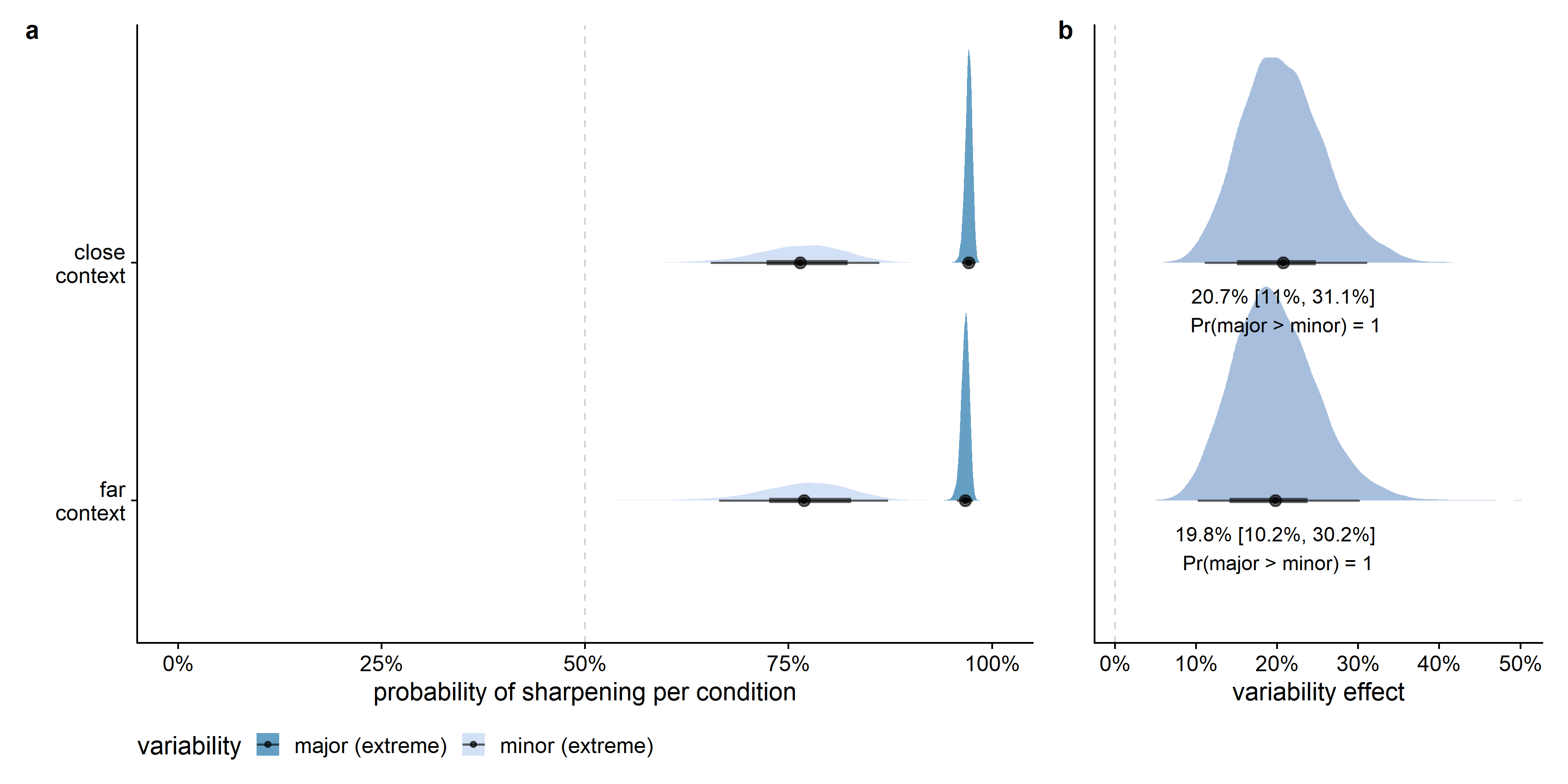
Just as in the models using the other interpretations of leveling and sharpening, the estimated variability between feature dimensions was larger for the differences between the variability and extremeness conditions than for the context effect (see Figure D.10), and the estimated variability between feature dimensions was higher than the estimated variability between participants, which is potentially also a consequence of the limited number of data points per participant in comparison to the number of data points per feature dimension.
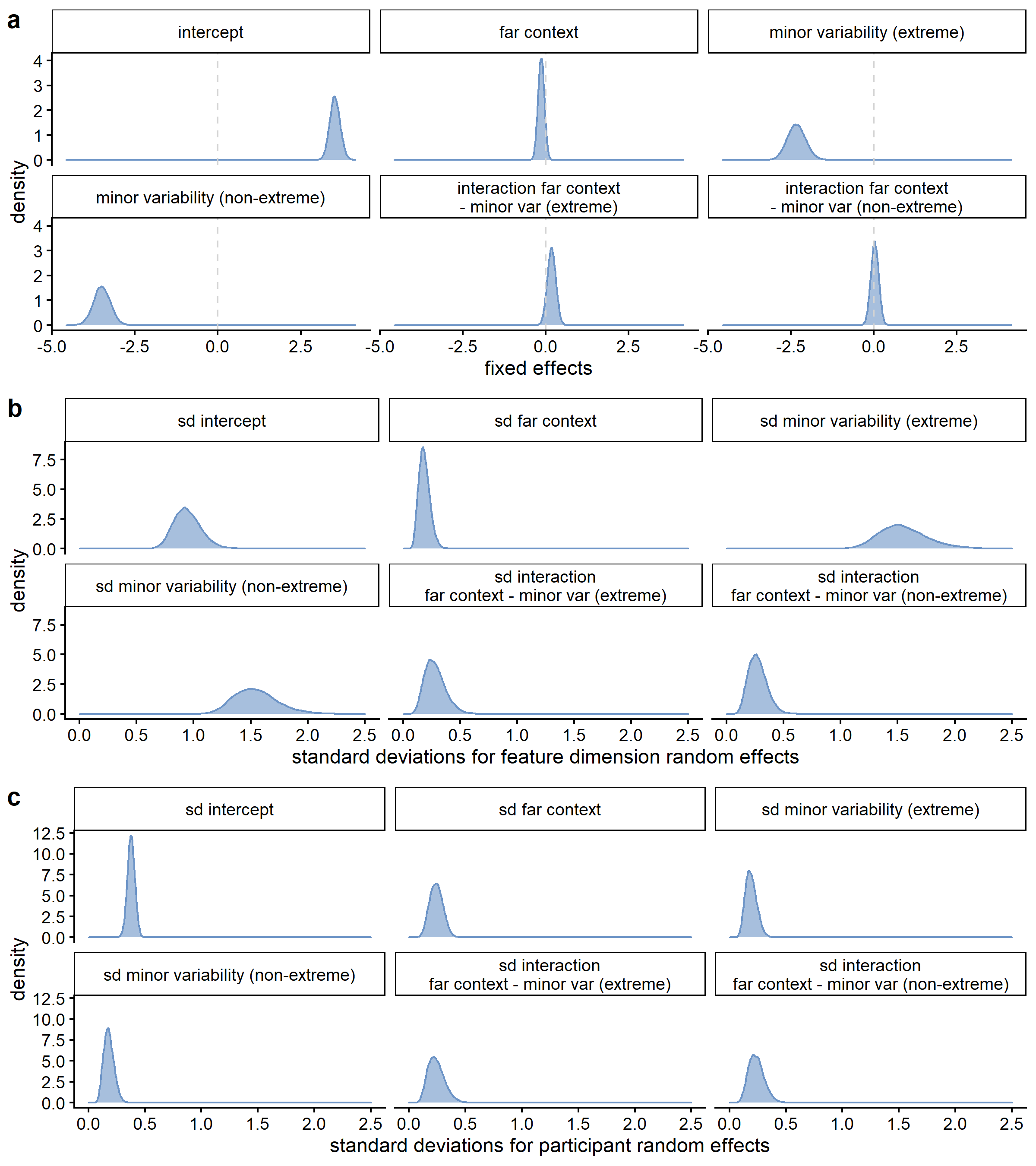
Figure D.11 shows the results for the equivalent qualitative model of sharpening based on the absolute rather than the relative feature values.
D.2.3 Additional quantitative results
When inspecting the standard deviations for the feature dimension random effects (see Figure D.12), the estimated variability between feature dimensions was slightly larger for the differences between the variability conditions than for the context effect, but the difference in variability seemed less outspoken than in the qualitative analysis (see also Figure D.13). As in the other models, the estimated variability between feature dimensions was higher than the estimated variability between participants (see also Figure D.14).
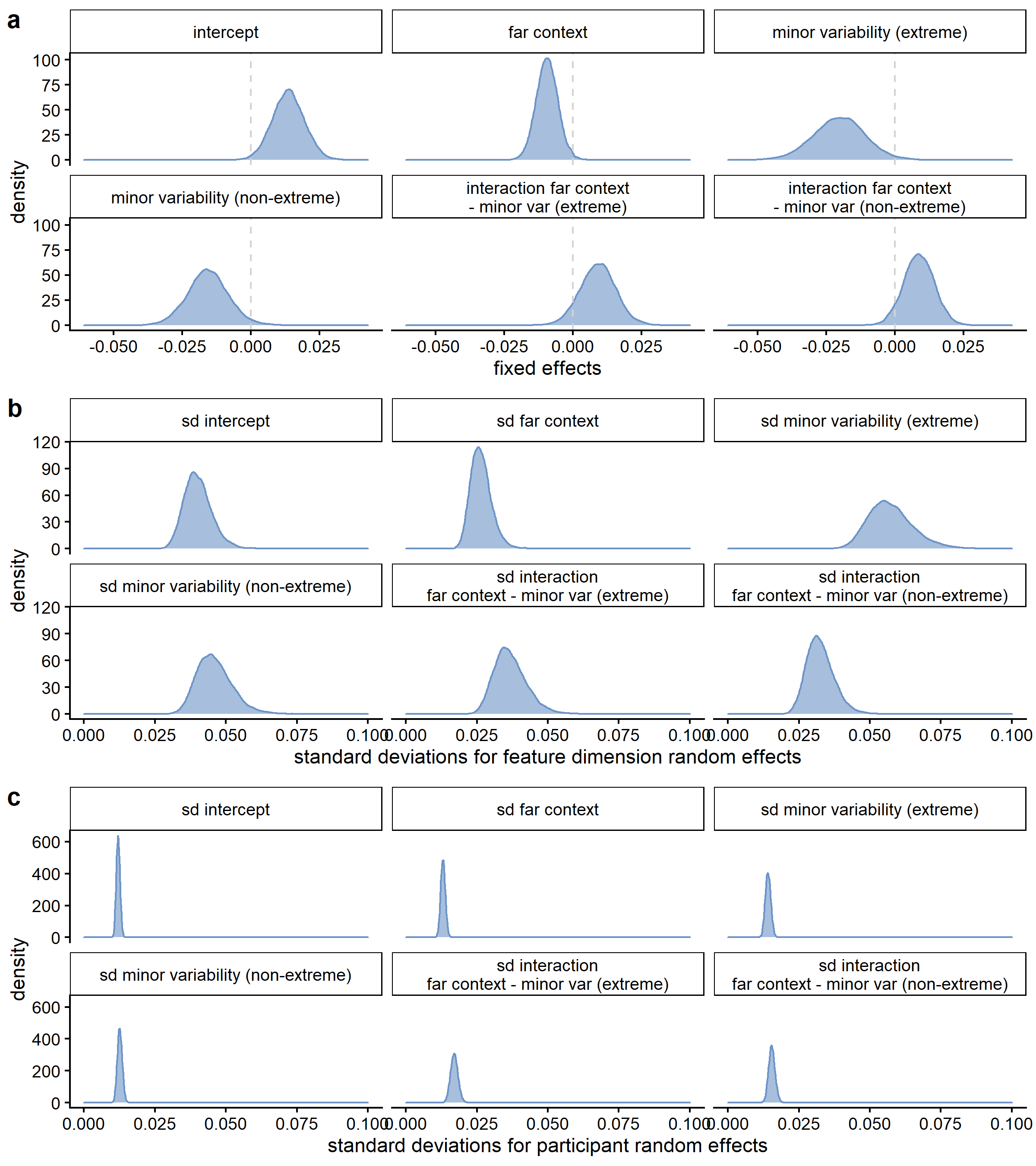
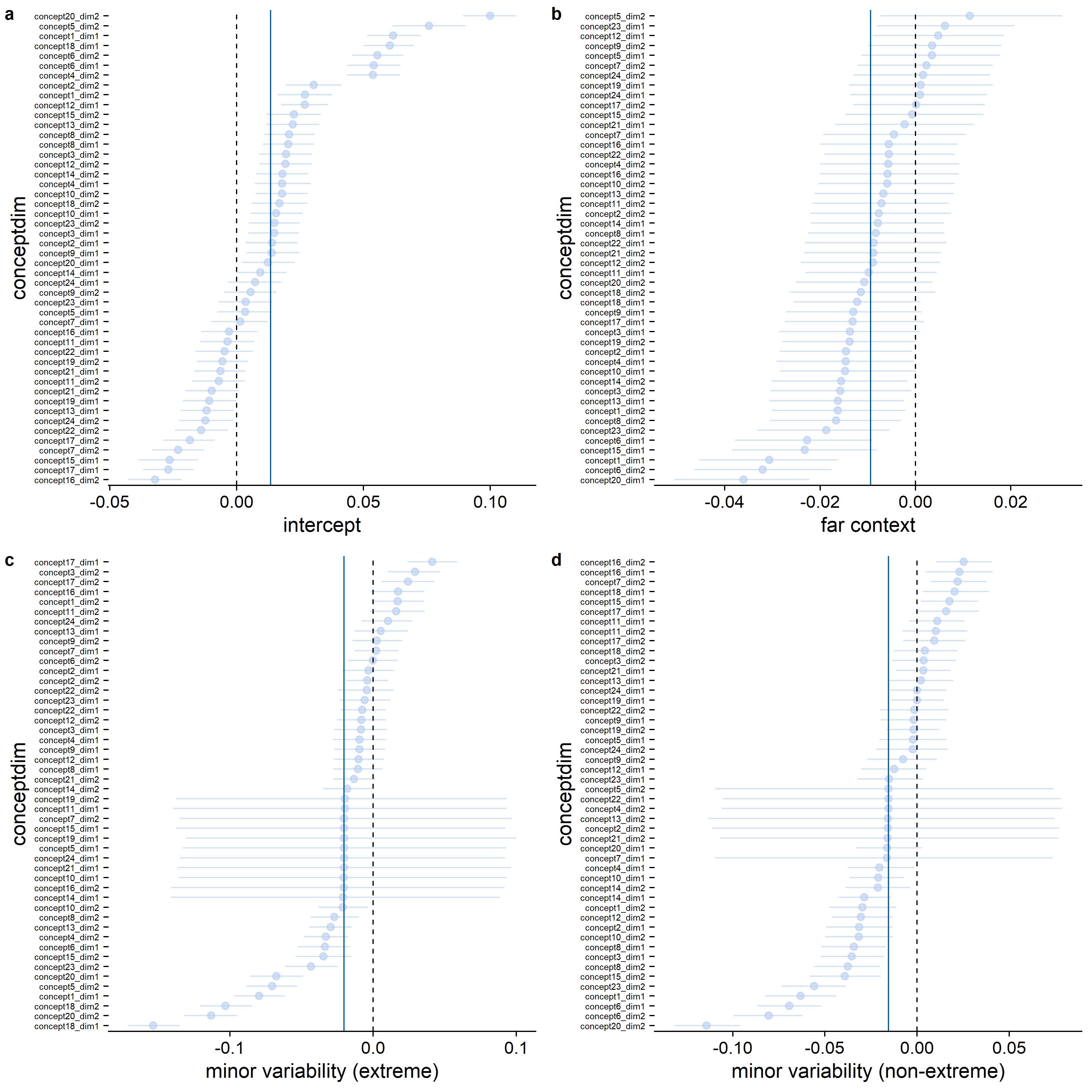

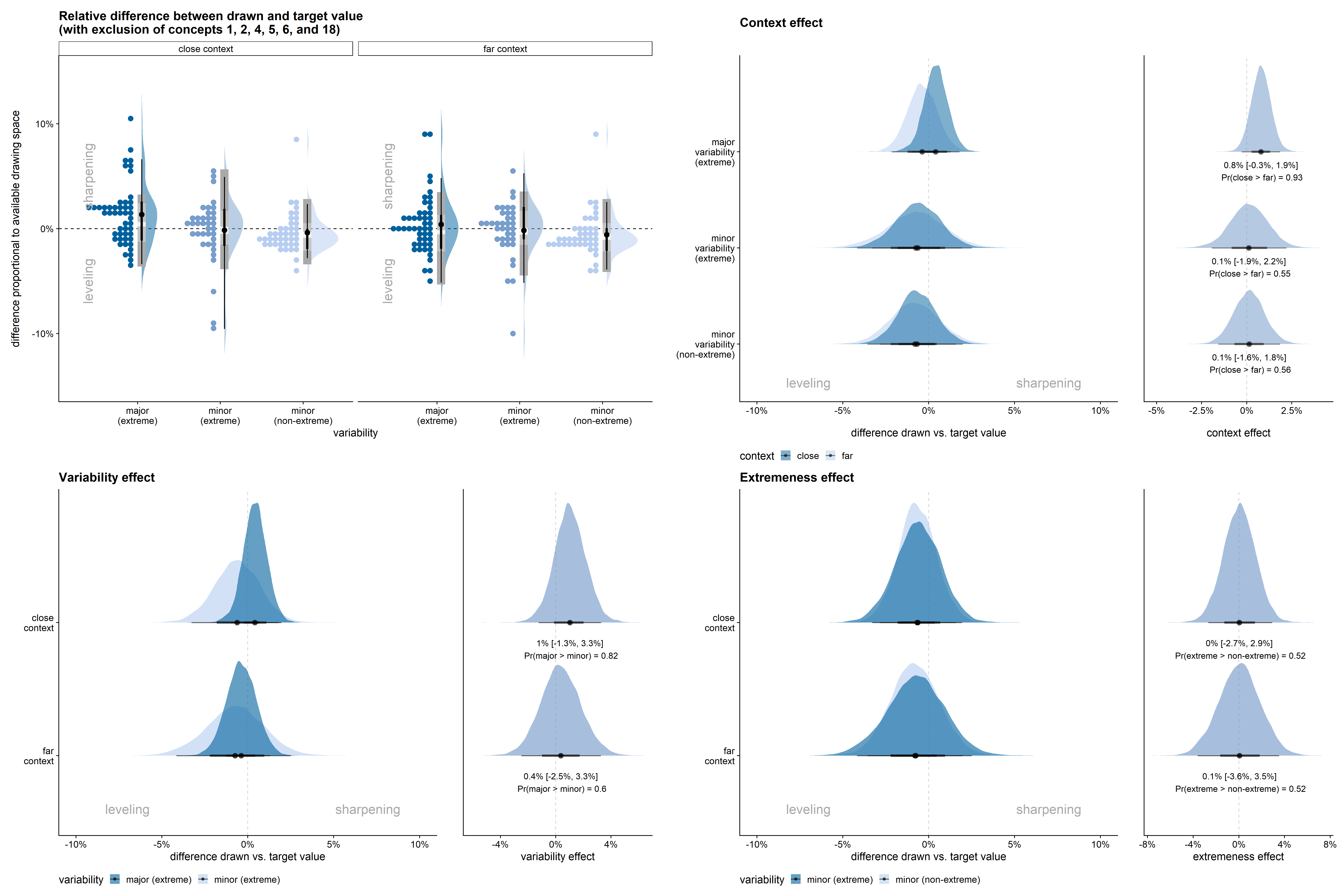
Figure D.15 shows the results for the quantitative model of sharpening based on the relative feature values, but with exclusion of concepts 1, 2, 4, 5, 6, and 18.
D.3 Supplemental videos
In the HTML version of this Appendix, you can find screen recordings of some components that were part of this study (cf. Figure D.16).

Due to rounding errors, the size of the steps between the different values on a feature dimension was not always exactly equal, especially for the feature dimensions with minor variability. In addition, when constructing the stimuli, some errors were made in the minimum or maximum value for the dimension with minor variability for designs 5 (maximum value dimension 1 in series B 28.25 instead of 28.75), 16 (minimum value dimension 1 in series B 30 instead of 31.2), and 22 (minimum value dimension 1 in series B 23.8 instead of 21.2 and maximum value dimension 1 in series B 31.2 instead of 28.8).↩︎
For designs 1, 2, and 6, one of the feature dimensions was bidirectional, which required the step size to be added at both sides of the figure. Therefore, in these designs, the smallest steps were one out of two or one out of eight of the largest steps available concurrently for the other feature dimension in the figure. When comparing major and minor variability for the same feature dimension across the A and B series, the ratio of one out of four is correct.↩︎
One downside of this rescaling procedure is that the height and/or width of the two drawn shapes becomes dependent, potentially indirectly leading to dependent feature values on both dimensions. The rescaling can also lead to feature values relative to the available drawing space that are smaller than -1 or larger than 1. We therefore also conducted the analyses with exclusion of these six designs, which led to slightly smaller but similar qualitative and quantitative results as presented in the main text (see Figure D.5 and Figure D.15).↩︎